
Create README.md
Browse files
README.md
ADDED
|
@@ -0,0 +1,120 @@
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 1 |
+
---
|
| 2 |
+
language: en
|
| 3 |
+
tags:
|
| 4 |
+
- SEGA
|
| 5 |
+
- data augmentation
|
| 6 |
+
- keywords-to-text generation
|
| 7 |
+
- sketch-to-text generation
|
| 8 |
+
license: apache-2.0
|
| 9 |
+
datasets:
|
| 10 |
+
- c4
|
| 11 |
+
|
| 12 |
+
|
| 13 |
+
widget:
|
| 14 |
+
- text: "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
|
| 15 |
+
example_title: "Example 1"
|
| 16 |
+
- text: "<mask> machine learning <mask> my research interest <mask> data science <mask>"
|
| 17 |
+
example_title: "Example 2"
|
| 18 |
+
- text: "<mask> play basketball <mask> a strong team <mask> Shanghai University of Finance and Economics <mask> last Sunday <mask>"
|
| 19 |
+
example_title: "Example 3"
|
| 20 |
+
- text: "Good news: <mask> the European Union <mask> month by EU <mask> Farm Commissioner Franz <mask>"
|
| 21 |
+
example_title: "Example with a prompt 1"
|
| 22 |
+
- text: "Bad news: <mask> the European Union <mask> month by EU <mask> Farm Commissioner Franz <mask>"
|
| 23 |
+
example_title: "Example with a prompt 2"
|
| 24 |
+
|
| 25 |
+
inference:
|
| 26 |
+
parameters:
|
| 27 |
+
max_length: 200
|
| 28 |
+
num_beams: 3
|
| 29 |
+
do_sample: True
|
| 30 |
+
---
|
| 31 |
+
|
| 32 |
+
# SEGA-large model
|
| 33 |
+
|
| 34 |
+
**SEGA: SkEtch-based Generative Augmentation** \
|
| 35 |
+
**基于草稿的生成式增强模型**
|
| 36 |
+
|
| 37 |
+
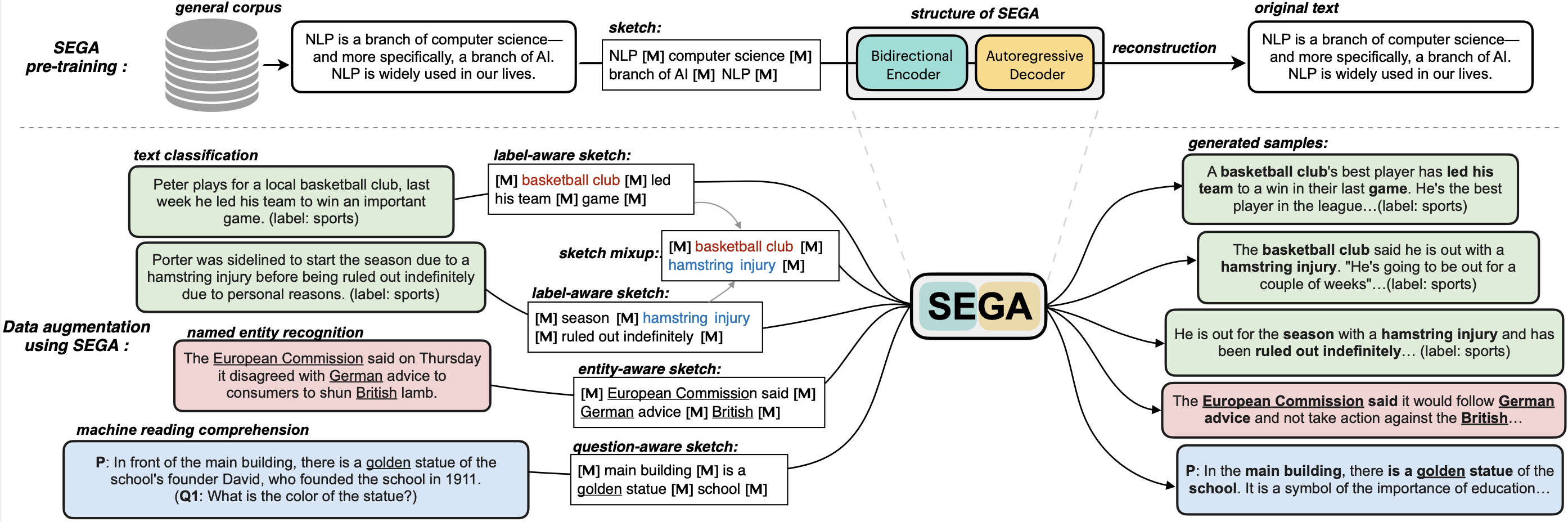
**SEGA** is a **general text augmentation model** that can be used for data augmentation for **various NLP tasks** (including sentiment analysis, topic classification, NER, and QA). SEGA uses an encoder-decoder structure (based on the BART architecture) and is pre-trained on the `C4-realnewslike` corpus.
|
| 38 |
+
|
| 39 |
+
|
| 40 |
+
|
| 41 |
+
|
| 42 |
+
- Paper: [coming soon](to_be_added)
|
| 43 |
+
- GitHub: [SEGA](https://github.com/beyondguo/SEGA).
|
| 44 |
+
|
| 45 |
+
**SEGA** is able to write complete paragraphs given a *sketch*, which can be composed of:
|
| 46 |
+
- keywords /key-phrases, like "––NLP––AI––computer––science––"
|
| 47 |
+
- spans, like "Conference on Empirical Methods––submission of research papers––"
|
| 48 |
+
- sentences, like "I really like machine learning––I work at Google since last year––"
|
| 49 |
+
- or mixup~
|
| 50 |
+
|
| 51 |
+
|
| 52 |
+
**Model variations:**
|
| 53 |
+
| Model | #params | Language | comment|
|
| 54 |
+
|------------------------|--------------------------------|-------|---------|
|
| 55 |
+
| [`sega-large`](https://huggingface.co/beyond/sega-large) | 406M | English | The version used in paper |
|
| 56 |
+
| [`sega-large-k2t`](https://huggingface.co/beyond/sega-large-k2t) | 406M | English | keywords-to-text |
|
| 57 |
+
| [`sega-base`](https://huggingface.co/beyond/sega-base) | 139M | English | smaller version |
|
| 58 |
+
| [`sega-base-ps`](https://huggingface.co/beyond/sega-base) | 139M | English | pre-trained both in paragraphs and short sentences |
|
| 59 |
+
| [`sega-base-chinese`](https://huggingface.co/beyond/sega-base-chinese) | 116M | 中文 | 在一千万纯净中文段落上预训练|
|
| 60 |
+
|
| 61 |
+
---
|
| 62 |
+
|
| 63 |
+
### How to use
|
| 64 |
+
#### 1. If you want to generate sentences given a **sketch**
|
| 65 |
+
```python
|
| 66 |
+
from transformers import pipeline
|
| 67 |
+
# 1. load the model with the huggingface `pipeline`
|
| 68 |
+
sega = pipeline("text2text-generation", model='beyond/sega-large', device=0)
|
| 69 |
+
# 2. provide a sketch (joint by <mask> tokens)
|
| 70 |
+
sketch = "<mask> Conference on Empirical Methods <mask> submission of research papers <mask> Deep Learning <mask>"
|
| 71 |
+
# 3. just do it!
|
| 72 |
+
generated_text = sega(sketch, num_beams=3, do_sample=True, max_length=200)[0]['generated_text']
|
| 73 |
+
print(generated_text)
|
| 74 |
+
```
|
| 75 |
+
Output:
|
| 76 |
+
```shell
|
| 77 |
+
'The Conference on Empirical Methods welcomes the submission of research papers. Abstracts should be in the form of a paper or presentation. Please submit abstracts to the following email address: eemml.stanford.edu. The conference will be held at Stanford University on April 1618, 2019. The theme of the conference is Deep Learning.'
|
| 78 |
+
```
|
| 79 |
+
|
| 80 |
+
#### 2. If you want to do **data augmentation** to generate new training samples
|
| 81 |
+
Please Check our Github page: [github.com/beyondguo/SEGA](https://github.com/beyondguo/SEGA), where we provide ready-to-run scripts for data augmentation for text classification/NER/MRC tasks.
|
| 82 |
+
|
| 83 |
+
---
|
| 84 |
+
|
| 85 |
+
## SEGA as A Strong Data Augmentation Tool:
|
| 86 |
+
- Setting: Low-resource setting, where only n={50,100,200,500,1000} labeled samples are available for training. The below results are the average of all training sizes.
|
| 87 |
+
- Datasets: [HuffPost](https://huggingface.co/datasets/khalidalt/HuffPost), [BBC](https://huggingface.co/datasets/SetFit/bbc-news), [SST2](https://huggingface.co/datasets/glue), [IMDB](https://huggingface.co/datasets/imdb), [Yahoo](https://huggingface.co/datasets/yahoo_answers_topics), [20NG](https://huggingface.co/datasets/newsgroup).
|
| 88 |
+
- Base classifier: [DistilBERT](https://huggingface.co/distilbert-base-cased)
|
| 89 |
+
|
| 90 |
+
|
| 91 |
+
In-distribution (ID) evaluations:
|
| 92 |
+
| Method | Huff | BBC | Yahoo | 20NG | IMDB | SST2 | avg. |
|
| 93 |
+
|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|
|
| 94 |
+
| none | 79.17 | **96.16** | 45.77 | 46.67 | 77.87 | 76.67 | 70.39 |
|
| 95 |
+
| EDA | 79.20 | 95.11 | 45.10 | 46.15 | 77.88 | 75.52 | 69.83 |
|
| 96 |
+
| BackT | 80.48 | 95.28 | 46.10 | 46.61 | 78.35 | 76.96 | 70.63 |
|
| 97 |
+
| MLM | 80.04 | 96.07 | 45.35 | 46.53 | 75.73 | 76.61 | 70.06 |
|
| 98 |
+
| C-MLM | 80.60 | 96.13 | 45.40 | 46.36 | 77.31 | 76.91 | 70.45 |
|
| 99 |
+
| LAMBADA | 81.46 | 93.74 | 50.49 | 47.72 | 78.22 | 78.31 | 71.66 |
|
| 100 |
+
| STA | 80.74 | 95.64 | 46.96 | 47.27 | 77.88 | 77.80 | 71.05 |
|
| 101 |
+
| **SEGA** | 81.43 | 95.74 | 49.60 | 50.38 | **80.16** | 78.82 | 72.68 |
|
| 102 |
+
| **SEGA-f** | **81.82** | 95.99 | **50.42** | **50.81** | 79.40 | **80.57** | **73.17** |
|
| 103 |
+
|
| 104 |
+
Out-of-distribution (OOD) evaluations:
|
| 105 |
+
| | Huff->BBC | BBC->Huff | IMDB->SST2 | SST2->IMDB | avg. |
|
| 106 |
+
|------------|:----------:|:----------:|:----------:|:----------:|:----------:|
|
| 107 |
+
| none | 62.32 | 62.00 | 74.37 | 73.11 | 67.95 |
|
| 108 |
+
| EDA | 67.48 | 58.92 | 75.83 | 69.42 | 67.91 |
|
| 109 |
+
| BackT | 67.75 | 63.10 | 75.91 | 72.19 | 69.74 |
|
| 110 |
+
| MLM | 66.80 | 65.39 | 73.66 | 73.06 | 69.73 |
|
| 111 |
+
| C-MLM | 64.94 | **67.80** | 74.98 | 71.78 | 69.87 |
|
| 112 |
+
| LAMBADA | 68.57 | 52.79 | 75.24 | 76.04 | 68.16 |
|
| 113 |
+
| STA | 69.31 | 64.82 | 74.72 | 73.62 | 70.61 |
|
| 114 |
+
| **SEGA** | 74.87 | 66.85 | 76.02 | 74.76 | 73.13 |
|
| 115 |
+
| **SEGA-f** | **76.18** | 66.89 | **77.45** | **80.36** | **75.22** |
|
| 116 |
+
|
| 117 |
+
|
| 118 |
+
|
| 119 |
+
### BibTeX entry and citation info
|
| 120 |
+
|