
K2-V2
Collection
The collection for K2-V2 models. • 7 items • Updated • 17
📚 Tech Report - 📝 Training Code - 🏢 Evaluation Code
🗂️ Pretraining Data: TxT360 - 🗂️ Midtraining Data: TxT360-Midas - 🗂️ SFT Data: TxT360-3efforts
K2-V2 is our most capable fully open model to date, and one of the strongest open-weight models in its class. It uses a 70B-parameter dense transformer architecture and represents the latest advancement in the LLM360 model family.


Beyond standard competencies such as factual knowledge and conversational ability, K2-V2 demonstrates strong long-context consistency, deep mathematical understanding, and robust reasoning skills. These capabilities serve as building blocks for sophisticated downstream applications, such as solving complex math problems and executing agentic workflows.
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("LLM360/K2-V2", device_map="auto")
tokenizer = AutoTokenizer.from_pretrained("LLM360/K2-V2")
prompt = "Explain why the derivative of sin(x) is cos(x)."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
To make experimentation easier, we uploaded multiple checkpoints from each pretraining and midtraining stage as tagged releases. These checkpoints follow a consistent naming convention.
Checkpoints from different stages use the stage name as a prefix: base, mid_1, mid_2, mid_3, and mid_4. Final checkpoints are marked with the final suffix, while intermediate checkpoints are identified by their checkpoint numbers.
For example, the final checkpoint from midtraining stage 4 is named mid_4_final.
Quick links to all the final checkpoints for different stages:
To use a specific checkpoint, use the revision argument:
model = AutoModelForCausalLM.from_pretrained("llm360/k2-v2", device_map="auto", revision="base_0720000")
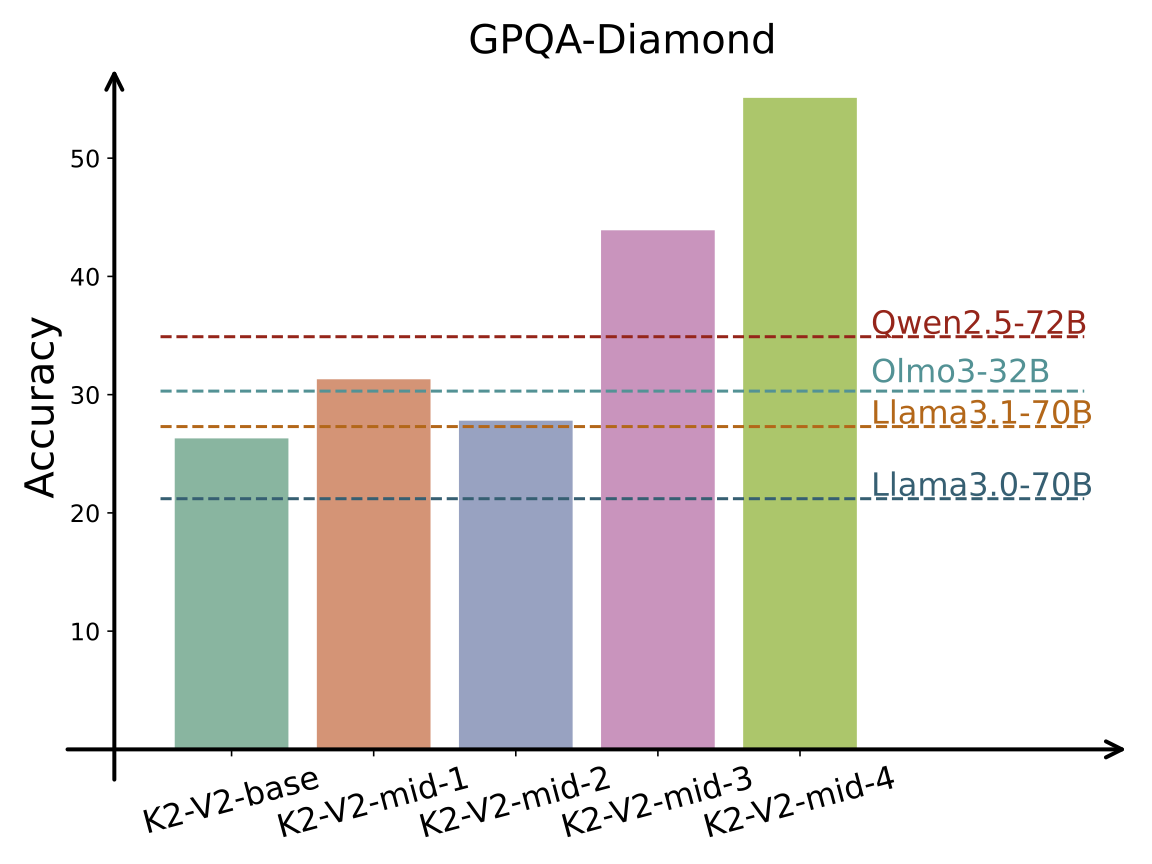
Below we report performance across general, reasoning, mathematical, and coding benchmarks. Scores for K2-V2 checkpoints (base → mid-4) demonstrate the impact of staged mid-training on reasoning quality.
| Task / Model | base | mid-1 | mid-2 | mid-3 | mid-4 | Qwen2.5-72B | Llama3.0-70B | Llama3.1-70B | Olmo3-32B |
|---|---|---|---|---|---|---|---|---|---|
| General Tasks | |||||||||
| MMLU | 74.3 | 74.4 | 73.5 | 75.0 | 75.2 | 86.1 | 79.5 | 79.3 | 75.2 |
| MMLU-Pro | 43.7 | 46.8 | 48.1 | 59.8 | 57.0 | 58.1 | 52.8 | 53.8 | 49.6 |
| BBH | 68.4 | 79.8 | 81.1 | 82.2 | 83.2 | 86.3 | 82.2 | 82.1 | 77.6 |
| HELLASWAG | 87.8 | 86.9 | 86.6 | 86.6 | 86.0 | 87.6 | 88.0 | 85.0 | 84.8 |
| WINOGRANDE | 82.6 | 83.7 | 83.7 | 83.7 | 83.0 | 83.9 | 85.3 | 79.8 | 90.3 |
| PIQA | 84.2 | 84.0 | 83.3 | 82.9 | 83.1 | 83.5 | 84.6 | 84.3 | 85.6 |
| TRUTHFULQA | 54.0 | 54.9 | 55.1 | 55.8 | 53.9 | 60.5 | 45.6 | 49.7 | 54.9 |
| Math & STEM Tasks | |||||||||
| GPQA-DIAMOND | 26.3 | 31.3 | 27.8 | 43.9 | 55.1 | 34.9 | 21.2 | 27.3 | 30.3 |
| GSM8K | 68.0 | 76.4 | 82.1 | 93.6 | 92.5 | 91.2 | 83.2 | 81.1 | 80.5 |
| MATH | 27.8 | 38.2 | 41.1 | 94.7 | 91.4 | 58.5 | 41.9 | 41.6 | 43.4 |
| AIME 2025 | 0.0 | 17.6 | 25.1 | 53.2 | 46.9 | 1.7 | 0.1 | 0.2 | 14.7 |
| ARC-CHALLENGE | 64.9 | 66.4 | 66.4 | 66.0 | 66.3 | 72.4 | 69.2 | 64.9 | 65.4 |
| Coding Tasks | |||||||||
| MBPP | 57.6 | 57.8 | 58.2 | 59.8 | 61.8 | 75.4 | 69.2 | 64.4 | 60.2 |
| HUMANEVAL | 50.0 | 51.2 | 53.7 | 54.3 | 54.3 | 54.3 | 42.1 | 50.6 | 36.0 |
| Logic Puzzles | |||||||||
| COUNTDOWN | 1.3 | 53.3 | 53.1 | 35.9 | 75.6 | 6.0 | 1.0 | 0.5 | 23.2 |
| KK-4 PEOPLE | 4.8 | 44.9 | 68.0 | 64.5 | 92.9 | 26.1 | 4.2 | 7.6 | 42.4 |
| KK-8 PEOPLE | 0.5 | 23.2 | 41.3 | 51.6 | 82.8 | 5.7 | 1.1 | 1.3 | 13.0 |
| ORDER-15 ITEMS | 4.7 | 30.7 | 47.2 | 55.8 | 87.6 | 37.0 | 3.5 | 4.5 | 25.0 |
| ORDER-30 ITEMS | 0.0 | 0.3 | 3.0 | 34.1 | 40.3 | 0.7 | 0.2 | 0.1 | 0.6 |
| Instruction Following | |||||||||
| IFEVAL | 17.4 | 26.2 | 28.5 | 34.5 | 26.7 | 40.3 | 15.1 | 17.4 | 13.2 |
| Arabic | |||||||||
| MMLU-Arabic | 65.4 | 66.1 | 64.5 | 66.6 | 65.5 | 74.1 | 65.0 | 66.8 | 47.8 |
Below we report the evaluation results for K2-V2 after supervised fine-tuning (SFT). These variants correspond to three levels of reasoning effort (Low < Medium < High).
| Metric / Model | K2 Low Dense · 70B |
K2 Medium Dense · 70B |
K2 High Dense · 70B |
Olmo3 Think SFT Dense · 32B · No RL |
Olmo3 Think Dense · 32B · RL |
GLM-4.5 Air MoE · 106B A12B |
MiniMax-M2 MoE · 230B A10B |
Qwen3 235B MoE · 235B A22B · Reasoning |
Qwen 2.5 72B Dense · 72B |
|---|---|---|---|---|---|---|---|---|---|
| LongBench V2 | 40.7 | 41.3 | 42.6 | 42.8 | 47.1 | 49.4 | 55.8 | 60.9 | 47.2 |
| AIME25 | 27.3 | 62.0 | 80.2 | 68.3 | 73.3 | 81.3 | 75.8 | 88.8 | 15.2 |
| HMMT25 | 19.0 | 45.6 | 71.4 | 43.3 | 50.83 | 73.3 | 63.5 | 84.2 | 9.79 |
| GSM8K | 92.4 | 92.0 | 94.8 | 96.1 | 95.7 | 96.1 | 95.4 | 93.5 | 85.8 |
| Minerva | 85.0 | 90.6 | 94.5 | 96.9 | 97.3 | 94.9 | 85.3 | 98.0 | 82.1 |
| GPQA-D | 48.5 | 60.6 | 69.3 | 58.0 | 59.8 | 75.3 | 76.2 | 80.7 | 50.5 |
| MBPP | 71.0 | 75.8 | 84.8 | 87.6 | 91.6 | 82.8 | 83.8 | 96.2 | 80.0 |
| HumanEval | 82.3 | 91.5 | 91.5 | 96.3 | 96.3 | 97.6 | 89.6 | 94.5 | 85.4 |
| LCBv6 | 39.9 | 51.3 | 67.0 | 67.9 | 67.6 | 67.8 | 79.2 | 72.8 | 36.7 |
Please refer to our Tech Report for detailed evaluation results.
K2-V2 training is organized into three stages, each using a transparent, publicly released mixture:
All mixtures, filtering rules, and data sources are fully released for reproducibility.
Please refer to our Tech Report for detailed datasets and mixtures information.
| Model Hyperparameter | Value |
|---|---|
| Total Parameters | 70B |
| Hidden Size | 8,192 |
| Intermediate Size (FFN) | 28,672 |
| Number of Attention Heads | 64 |
| Number of Layers | 80 |
| RMSNorm ɛ | 1e-5 |
| Pre-training Seq Length | 8,192 |
| Max Mid-training Seq Length | 524,288 |
| Vocab Size | 250,000 |
K2-V2 is designed for:
K2-V2 is not instruction-tuned. For aligned conversational use, please see K2-V2-Instruct.
If you use K2-V2 in your research, please cite the following:
@misc{k2team2025k2v2360openreasoningenhancedllm,
title={K2-V2: A 360-Open, Reasoning-Enhanced LLM},
author={K2 Team and Zhengzhong Liu and Liping Tang and Linghao Jin and Haonan Li and Nikhil Ranjan and Desai Fan and Shaurya Rohatgi and Richard Fan and Omkar Pangarkar and Huijuan Wang and Zhoujun Cheng and Suqi Sun and Seungwook Han and Bowen Tan and Gurpreet Gosal and Xudong Han and Varad Pimpalkhute and Shibo Hao and Ming Shan Hee and Joel Hestness and Haolong Jia and Liqun Ma and Aaryamonvikram Singh and Daria Soboleva and Natalia Vassilieva and Renxi Wang and Yingquan Wu and Yuekai Sun and Taylor Killian and Alexander Moreno and John Maggs and Hector Ren and Guowei He and Hongyi Wang and Xuezhe Ma and Yuqi Wang and Mikhail Yurochkin and Eric P. Xing},
year={2025},
eprint={2512.06201},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2512.06201},
}